
국내 연구진이 사람처럼 문서를 이해하고 정보를 찾을 수 있는 AI 기술을 개발했다.
한국전자통신연구원(ETRI)은 오피스 문서로부터 사용자 질문에 정답을 알려주고 두 문장이 같은 의미인지 이해하는 API(운영 체제 기능 제어 인터페이스) 2종을 개발했다고 7일 밝혔다.
그동안 다양한 업무 관련 정보와 지식들을 전자문서로 저장하는 형태로 만들고 있지만, 제목과 파일 이름 포함 단어를 일일이 검색해야 한는 등 효율성이 떨어졌다.
이에 ETRI는 인공지능 SW를 이용해 원하는 정보를 검색할 뿐 아니라 질문에 정답과 근거까지 확인할 수 있는 기술을 개발했다.
행정문서 질의응답(QA) API 기술은 딥러닝 언어모델을 이용해 단락과 표를 인식하여 정답 및 근거 문장을 인식하는 기술이다. 예를 들어 ‘출장 경비가 100만 원 들 때, 결재를 어느 선까지 받아야 할까요?’라는 질문을 입력하면, ‘100만 원 이하인 경우, 실장 전결’과 같은 사내 규정 정보를 담은 문서와 그 근거 부분까지 찾아 준다.
이 기술은 공동연구기관인 한글과컴퓨터에서 블라인드 평가로 정확도를 측정했다. 그 결과 단락을 대상으로 검색해 나온 상위 5개 결과의 정확도는 89.65%, 표를 대상으로 진행한 검색에서는 81.5%로 높은 정확도를 보였다.
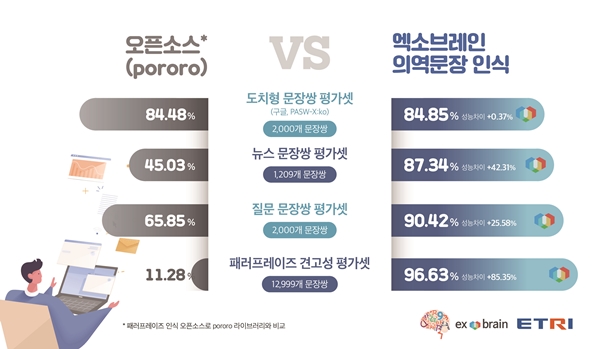
또 패러프레이즈(Paraphrase) 인식 API는 사람처럼 똑똑하게 문서를 보고 다른 형태의 문장이 같은 뜻을 지니는지 파악하는 기술이다. 행정문서QA API와 다른 한국어 AI 개발에도 쓰일 수 있는 원천 기술이다.
인공지능과 딥러닝 기술은 사람과 달리 문장이 조금만 달라져도 의미 관계를 올바르게 인식하지 못하는 견고성(robustness) 문제가 있었다.
‘그는 빨간 자전거를 샀다’와 ‘그가 산 자전거는 빨간색이다’라는 문장은 사람과 기계가 쉽게 구분하지만, ‘그는 빨간 자전거를 안 샀다’라는 문장과는 구분을 잘하지 못한다.
ETRI는 이런 한계를 개선해 다양한 유형의 문장에서 의미 관계를 인식하도록 본 기술을 개발했다. 견고성 평가셋 대상 평가 결과, 96.63% 정확도를 보이며 기존 오픈소스 딥러닝 기술보다 성능을 크게 개선할 수 있었다.
연구진은 “오피스 문서 서식이 다양하고 정형화되지 않아 인공지능 기술을 적용하기 어려웠지만, 견고성이 높은 데이터를 구축하고 무엇이 문제인지 판단하는 알고리즘 성능을 높이면서 성과를 낼 수 있었다”고 설명했다.
향후 GPT-3(딥러닝 텍스트 자동 회귀 언어 모델)에 대응해 언어이해와 생성을 동시에 학습한 딥러닝 언어모델을 개발하고 관련 기술을 공개하면서 AI 기술력을 고도화하고 플랫폼 개발에도 기여한다는 계획이다.
ETRI 언어지능연구실 임준호 박사는 “한국어 인공지능 서비스 시장이 더욱 활성화되어 외산 인공지능 솔루션의 국내시장 잠식을 막고 국민들이 유용한 지식 정보를 쉽고 빠르게 습득할 수 있는데 도움이 되기를 기대한다”고 말했다.
한편 이번 기술은 ETRI 공공 인공지능 오픈 API·데이터 서비스 포털에 공개돼 누구나 쉽게 이용할 수 있다.
