[충청뉴스 이성현 기자] 국내 연구진이 단 몇 개의 영상만으로 AI가 인간의 판단 기준을 스스로 학습하는 기술을 개발하며 피지컬 AI 상용화의 핵심 난제를 해결했다.
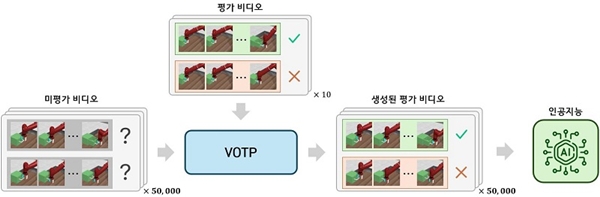
한국과학기술원(KAIST)은 전기및전자공학부 유창동 교수 연구팀이 수천~수만 건의 인간 평가 데이터 대신 단 몇 개의 선호 영상만으로도 AI가 인간의 의도와 판단 기준을 학습할 수 있는 새로운 기술인 ‘VOTP(Video-based Optimal TransPort Preference)’를 세계 최초로 개발했다고 10일 밝혔다.
연구팀의 논문은 오는 7월 서울 코엑스에서 개최되는 머신러닝 분야 세계 최고 권위의 학술대회인 ‘ICML(International Conference on Machine Learning) 2026’에 채택됐다.
특히 전체 제출 논문(2만3918편) 가운데 단 0.7%(168편)에만 주어지는 구두 발표 논문으로 선정되며 전 세계 AI 석학들로부터 연구의 우수성을 인정받았다.
최근 AI 기술은 글을 쓰고 그림을 그리는 생성형 AI를 넘어 실제 기계를 움직이고 현실 세계에서 행동하는 ‘피지컬 AI(Physical AI)’ 시대로 빠르게 진화하고 있다. 공장의 정밀 제조 로봇, 스스로 도로 상황을 판단하는 자율주행차, 정교한 수술을 수행하는 의료 로봇 등이 대표적이다.
하지만 기계가 수행한 행동이 인간의 의도에 맞는지, 어떤 행동이 더 바람직한지를 판단하는 인간 수준의 평가 기준을 학습하는 문제 등 피지컬 AI의 실용화를 위해서는 반드시 넘어야 할 장벽이 있었다.
이를 위해서는 인간의 선호와 판단 기준이 반영된 ‘보상함수(Reward Function)'가 필요하지만, 기존 방식은 사람이 최소 수천~수만 개의 행동 데이터를 직접 보고 일일이 평가해야 해 막대한 시간과 비용이 소요됐다.
데이터를 수집하는 비용을 줄이고자 대형 언어 모델(LLM) 등을 활용하기도 했으나, 모델 활용에 많은 비용이 들고 말로 표현하기 어려운 로봇의 미세한 움직임을 학습시키기 어렵다는 한계가 뚜렷했다.
연구팀은 사람이 몇 번의 시범만 보고도 새로운 일을 배우는 방식에 주목했다. 연구팀이 개발한 VOTP는 최신 비디오 인공지능의 시각적 이해 능력과 ‘최적 전송(Optimal Transport)’이라는 고도의 수학적 기법을 결합했다.
전 세계의 방대한 비디오를 학습한 비디오 인공지능이 로봇 행동의 미세한 차이를 포착하고, 이를 수학적 기법을 통해 인간의 의도를 파악하는 높은 수준의 평가를 가능하게 만든 것이다.
이로 인해 전문가가 제공한 단 몇 개의 좋은 시범과 나쁜 시범 영상만으로도 AI가 인간이 선호하는 행동 패턴을 스스로 파악하고, 수만 개의 일반적인 상황으로 확장해 옳고 그름을 유추하며 전문가 수준의 행동을 가속 학습할 수 있게 됐다.
이번 연구의 핵심 아이디어인 '소수의 인간 선호를 담은 비디오만으로 사람의 의도를 빠르게 파악하는 알고리즘'은 다양한 환경과 작업에 걸친 광범위한 실험을 통해 그 효과와 일반화 성능이 완벽히 입증됐다.
이러한 방식은 피지컬 AI 개발에 필요한 인간 피드백과 데이터 구축 비용을 획기적으로 줄여준다.
기업들이 새로운 로봇이나 자율주행 시스템을 개발할 때 전문가가 현장 영상 몇 개만 선별해 평가를 보여주면 인공지능이 이를 바탕으로 수많은 현장 영상을 스스로 분석해 최적의 동작을 학습하므로 바로 실무에 투입될 수 있다.
해당 기술은 로봇 팔 제어, 휴머노이드 로봇, 자율주행차, 스마트팩토리의 정밀 제조 공정, 드론, 수술 로봇의 미세 봉합뿐만 아니라, 인간을 대신해 컴퓨터 화면을 보고 스스로 작업을 수행하는 소프트웨어 AI 에이전트까지 무궁무진한 확장성을 가진다.
연구 과정에서 이론을 실제 환경에 적용하고 일관되게 안정적으로 학습하는 신뢰성을 확보하기까지 수많은 시행착오와 도전이 있었으나 이를 성공적으로 극복해 내며 핵심 원천 기술을 확보하는 데 성공했다.
연구팀은 향후 관련 기업들과의 산학 협력을 통해 제조 공정 및 서비스 로봇 분야에 이 기술을 시범 도입하여 상용화를 앞당길 계획이다.
유창동 교수는 “피지컬 AI의 핵심은 기계가 인간의 의도를 이해하고 올바른 행동을 선택하도록 만드는 것”이라며 “VOTP는 소수의 영상만으로 인간의 판단 기준을 학습할 수 있어, 로봇이 사람처럼 판단하는 시대를 앞당길 핵심 기술”이라고 설명했다.
이어 연구팀은 앞으로도 첨단 인공지능 모델의 빠른 발전 속도를 활용해 로봇 학습을 가속화할 수 있는 기술을 지속적으로 개발할 계획이며 나아가 이러한 기술을 통합해 '시각-언어-행동' 모델(VLA)과 같은 범용 로봇 인공지능의 학습 수준을 높이는 것을 핵심 목표로 두고 있다.
