한국과학기술원(KAIST)은 전삭학부 이재길 교수 연구팀이 적은 양의 훈련 데이터로도 높은 예측 정확도를 달성할 수 있는 새로운 모델 훈련 기술을 개발했다고 27일 밝혔다.
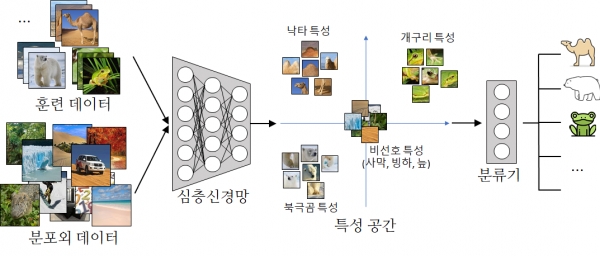
심층 학습 모델의 훈련은 주어진 훈련 데이터에서 레이블과 관련성이 높은 특성을 찾아내는 과정으로 볼 수 있다. 훈련 데이터가 불충분할 경우 바람직하지 않은 특성까지도 같이 추출될 수 있는 문제가 발생한다.
이 교수팀이 개발한 기술은 심층 학습 모델의 훈련에서 바람직하지 않은 특성을 억제해 충분하지 않은 훈련 데이터를 가지고도 높은 예측 정확도를 달성할 수 있게 해준다.
이 기술은 바람직하지 않은 특성을 억제하기 위해서 분포 외(out-of-distribution) 데이터를 활용한다. 예를 들어, 낙타와 호랑이 사진의 분류를 위한 훈련 데이터에 대해 여우 사진은 분포 외 데이터가 된다.
특히 다량의 분포 외 데이터를 추가로 활용해 여기에서 추출된 특성은 영(0) 벡터가 되도록 심층 학습 모델의 훈련 과정을 규제해 바람직하지 않은 특성의 효과를 억제한다.
훈련 과정을 규제한다는 측면에서 정규화 방법론의 일종이라 볼 수 있다. 분포 외 데이터는 쓸모없는 것이라 여겨지고 있었으나, 이번 기술에 의해 훈련 데이터 부족을 해소할 수 있는 유용한 보완재로 탈바꿈될 수 있다.
연구팀은 이 정규화 방법론을 `비선호(比選好) 특성 억제'라고 이름 붙이고 이미지 데이터 분석의 세 가지 주요 문제에 적용했다. 그 결과, 기존 최신 방법론과 비교했을 때, 이미지 분류 문제에서 최대 12% 예측 정확도를 향상했고, 객체 검출 문제에서 최대 3% 예측 정확도를 향상했으며, 객체 지역화 문제에서 최대 8% 예측 정확도를 향상했다.
이재길 교수는 "이 기술이 텐서플로우(TensorFlow) 혹은 파이토치(PyTorch)와 같은 기존의 심층 학습 라이브러리에 추가되면 기계 학습 및 심층 학습 학계에 큰 파급효과를 낼 수 있을 것ˮ이라고 밝혔다.
