[충청뉴스 이성현 기자] 국내 연구진이 기존에 공개된 영어 기반 거대 언어 모델(LLM)을 효율적인 방법으로 개량해 천문학적 비용을 들이지 않아도 ‘고성능 한국어 거대 언어 모델’ 개발이 가능함을 입증했다.
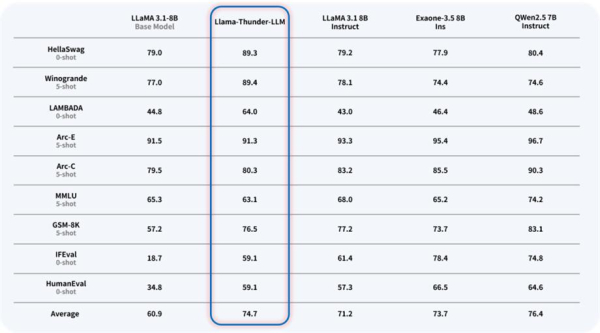
한국연구재단은 서울대학교 이재진 교수 연구팀이 영어 기반 언어 모델 라마(Llama)를 개량해 한국어에 특화된 언어 모델 'Llama-Thunder-LLM'과 한국어 전용 토크나이저 'Thunder-Tok', 한국어 LLM의 성능을 객관적으로 평가할 수 있는 'Thunder-LLM 한국어 벤치마크'를 개발해 온라인에 공개했다고 2일 밝혔다.
연구팀은 데이터 수집부터 사후 학습까지 언어 모델 학습의 모든 단계를 자체 진행하며 중국의 거대 언어 모델 딥시크(DeepSeek)처럼 제한된 자원으로도 고성능 언어 모델 구축이 가능함을 입증했다.
공개된 영어 모델을 활용했지만 적용한 기술은 독자적인 모델 개발에 필요한 모든 기술을 포함했다. 이는 연구팀이 고성능의 독자 언어 모델을 개발할 수 있는 기술 역량을 갖추고 있음을 시사한다.
연구팀이 개발한 Llama-Thunder-LLM은 3TB의 한국어 웹 데이터를 수집·전처리해 기존에 공개된 Llama 모델에 연속 학습과 사후 학습 등 개량 기법을 적용한 한국어 특화 거대 언어 모델이다.
한국어의 문법적 특성을 반영한 토크나이저 Thunder-Tok은 기존 Llama 토크나이저 대비 토큰 수를 약 44% 절약해 추론 속도 및 학습 효율성을 높였다.
연구팀이 자체 개발한 한국어 평가용 데이터셋을 포함한 Thunder-LLM 한국어 벤치마크는 한국어 LLM의 성능을 객관적이고 체계적으로 평가할 수 있는 기반을 제공한다.
이재진 교수는 “이번 연구는 학계도 자주적인 LLM 개발이 가능함을 입증하고 우리나라의 소버린 AI*에 기여한 의미 있는 결과”라며 “한국어 기반 LLM 및 토크나이저, 벤치마크 데이터셋을 온라인에 공개하고, 개발 과정 또한 상세히 기술해 누구나 후속 및 재현 연구에 활용할 수 있는 기반을 마련했다”고 말했다.
한편 이번 연구성과는 누구나 자유롭게 이용할 수 있도록 ‘초거대 AI모델 및 플랫폼 최적화 센터’ 웹페이지에 공개됐다.
