[충청뉴스 이성현 기자] 국내 연구진이 시간 제약 없이 일관되고 자연스러운 음성 생성을 실현한 ‘스피치SSM’을 개발하는데 성공했다.
한국과학기술원(KAIST)은 전기및전자공학부 노용만 교수 연구팀 박세진 박사과정이 장시간 음성 생성이 가능한 음성 언어 모델 ‘스피치SSM(SpeechSSM)’을 개발했다고 3일 밝혔다.
이번 연구는 국제 최고 권위 머신러닝 학회인 ICML(International Conference on Machine Learning) 2025에 전체 제출된 논문 중 약 1%만 선정되는 구두 논문 발표에 확정돼 뛰어난 연구 역량을 입증했다.
음성 언어 모델(SLM)은 중간에 텍스트로 변환하지 않고 음성을 직접 처리함으로써 인간 화자 고유의 음향적 특성을 활용할 수 있어 대규모 모델에서도 고품질의 음성을 빠르게 생성할 수 있다는 점이 큰 강점이다.
그러나 기존 모델은 음성을 아주 세밀하게 잘게 쪼개서 아주 자세한 정보까지 담는 경우, ‘음성 토큰 해상도’가 높아지고 사용하는 메모리 소비도 증가하는 문제로 인해 장시간 음성의 의미적, 화자적 일관성을 유지하기 어려웠다.
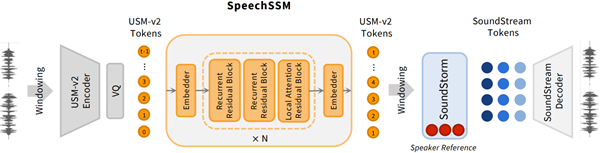
연구팀은 이러한 문제를 해결하기 위해 하이브리드 상태공간 모델을 사용한 음성 언어 모델인 ‘스피치SSM’를 개발해 긴 음성 시퀀스를 효율적으로 처리하고 생성할 수 있게 설계했다.
이 모델은 최근 정보에 집중하는 ‘어텐션 레이어(attention layer)’와 전체 이야기 흐름(장기적인 맥락)을 오래 기억하는 ‘순환 레이어(recurrent layer)’를 교차 배치한 ‘하이브리드 구조’를 통해 긴 시간 동안 음성을 생성해도 흐름을 잃지 않고 이야기를 잘 이어간다.
또 메모리 사용량과 연산량이 입력 길이에 따라 급격히 증가하지 않아, 장시간의 음성을 안정적이고 효율적으로 학습하고 생성할 수 있다.
스피치SSM은 음성 데이터를 짧은 고정된 단위로 나눠 각 단위별로 독립적으로 처리하고, 전체 긴 음성을 만들 경우에는 다시 붙이는 방식을 활용해 쉽게 긴 음성을 만들 수 있어 무한한 길이의 음성 시퀀스를 효과적으로 처리할 수 있게 했다.
아울러 음성 생성 단계에서는 한 글자, 한 단어 차례대로 천천히 만들어내지 않고, 여러 부분을 한꺼번에 빠르게 만들어내는 ‘비자기회귀(Non-Autoregressive)’방식의 오디오 합성 모델을 사용해, 고품질의 음성을 빠르게 생성할 수 있게 했다.
기존은 10초 정도 짧은 음성 모델을 평가했지만 연구팀은 16분까지 생성할 수 있도록 자체 구축한 새로운 벤치마크 데이터셋인 ‘LibriSpeech-Long'을 기반으로 음성을 생성하는 평가 태스크를 새롭게 만들었다.
기존 음성 모델 평가 지표인 말이 문법적으로 맞는지 정도만 알려주는 PPL(Perplexity)에 비해 연구팀은 시간이 지나면서도 내용이 잘 이어지는지 보는 'SC-L', 자연스럽게 들리는 정도를 시간 따라 보는 'N-MOS-T' 등 새로운 평가 지표들을 제안해 보다 효과적이고 정밀하게 평가했다.
박세진 박사과정은 “기존 음성 언어 모델은 장시간 생성에 한계가 있어, 실제 인간이 사용하도록 장시간 음성 생성이 가능한 음성 언어 모델을 개발하는 것이 목표였다”며 “이번 연구 성과를 통해 긴 문맥에서도 일관된 내용을 유지하면서, 기존 방식보다 더 효율적이고 빠르게 실시간으로 응답할 수 있어, 다양한 음성 콘텐츠 제작과 음성비서 등 음성 AI 분야에 크게 기여할 것으로 기대한다”고 설명했다.
