[충청뉴스 이성현 기자] 국내 연구진이 인공지능(AI) 심층학습(딥러닝) 서비스 구축 비용 최소화가 가능한 데이터 정제 기술을 개발했다.
한국과학기술원(KAIST)은 전산학부 이재길 교수 연구팀이 딥러닝 훈련 데이터 구축 비용을 최소화할 수 있는 새로운 데이터 동시 정제 및 선택 기술을 개발했다고 12일 밝혔다.
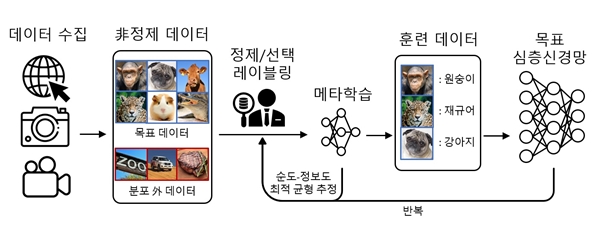
일반적으로 심층 학습용 훈련 데이터 구축 과정은 수집, 정제, 선택 및 레이블링 단계로 이뤄진다.
수집 단계에서는 웹, 카메라, 센서 등으로부터 대용량의 데이터가 정제되지 않은 채로 수집된다. 따라서 수집된 데이터에는 목표 서비스와 관련이 없어서 주어진 레이블에 해당하지 않는 분포 외 데이터가 포함된다.
이러한 분포 외 데이터는 데이터 정제 단계에서 정제돼야 한다. 모든 정제된 데이터에 정답지를 만들기 위해서는 막대한 비용이 소모되는데, 이를 최소화하기 위해 심층 학습 성능 향상에 가장 도움이 되는 훈련 데이터를 먼저 선택해 레이블링하는 능동 학습이 큰 주목을 받고 있다.
이재길 교수팀이 개발한 기술은 훈련 데이터 구축 단계에서 데이터의 정제 및 선택을 동시에 수행해 심층 학습용 훈련 데이터 구축 비용을 최소화할 수 있도록 해준다.
또 연구팀은 주어진 훈련 데이터 구축 비용 내에서 최고의 효과를 내도록 데이터의 순도 지표와 정보도 지표의 최적 균형을 찾아내기 위해 추가적인 작은 신경망 모델을 도입했다.
새롭게 선택돼 레이블링 된 데이터를 순도-정보도 최적 균형을 찾기 위한 훈련 데이터로 활용했고, 레이블이 추가될 때마다 최적 균형을 갱신했다.
연구팀은 이 메타학습 방법론을 `메타 질의 네트워크'라고 이름 붙이고 이미지 분류 문제에 대해 다양한 데이터와 광범위한 분포 외 데이터 비율에 걸쳐 방법론을 검증했다.
그 결과 기존 최신 방법론과 비교했을 때 최대 20% 향상된 최종 예측 정확도를 향상했고, 모든 범위의 분포 외 데이터 비율에서 일관되게 최고 성능을 보였다. 또 `메타 질의 네트워크'의 최적 균형 분석을 통해, 분포 외 데이터의 비율이 낮고 현재 심층신경망의 성능이 높을수록 정보도에 높은 가중치를 둬야 함을 연구팀은 밝혀냈다.
이재길 교수는 "이 기술이 텐서플로우 혹은 파이토치와 같은 기존의 심층 학습 라이브러리에 추가되면 기계 학습 및 심층 학습 학계에 큰 파급효과를 낼 수 있을 것ˮ이라고 설명했다.
